CMU15445 Lecture 9 Index Concurrency Control |
您所在的位置:网站首页 › page latch address › CMU15445 Lecture 9 Index Concurrency Control |
CMU15445 Lecture 9 Index Concurrency Control
|
除了redis, voltdb, h-store等,都会利用多核cpu,并尽量减少磁盘I/O的延迟,当然需要保证thread-safety CONCURRENCY CONTROLA concurrency control protocol需要保证正确性,其正确性的标准在于: **Logical Correctness: **线程必须能够完整正确的看到其应该看到的数据 Physical Correctness:数据内部是否完整合理,比如一个数据结构指针不会指向非法的内存地址 Locks & Latches区别是: Lock:是一个高层,逻辑上的原语,其在事务之间保护数据库的内容。 一个txn(transaction的简写)会全程持有lock 在查询执行时,数据库可以将lock暴露给用户 lock需要能够回滚变化,比如说,如果一个被lock锁上的tuple被修改了,这次修改可以回滚 Latch(有时又叫mutex):是一个底层保护原语,在线程之间,其用来保护DBMS内部数据结构的关键区域(比如,数据结构,内存区域) latch只有在操作执行的时候才会持有 latch并不需要能够回滚数据 存在两种latch mode READ:多个线程可以同时读,也就是线程可以持有read latch,即使是其他线程也持有read latch WRITE:,对于write latch,当一个thread持有时,其他thread就不能持有 Latch的实现Latch一般是由一个CPU提供的CAS(compare-and-swap)操作,CAS 的含义是“我认为原有的值应该是什么,如果是,则将原有的值更新为新值,否则不做修改,并告诉我这个值现在是多少”,就是比如设置一个值flag,当flag = false是,锁没有被其他人持有,这时可以将flag与true swap,并且这个compare and swap的操作是原子的,其他在执行compare时,就会卡住,直到第一个进程将flag的值swap回来。由三种实现latch的方法,它们都做了对于实现复杂度与执行时的效率之间的权衡: Blocking OS Mutex
需要OS介入,OS唤醒与睡眠一个线程的操作比较浪费时间,但是这种方法会用阻塞队列(比spin lock好),这样其他进程就不会一直占用cpu时间
两把锁? Test-and-Set Spin Latch (TAS)
自旋锁,非常浪费cpu时间,即使一个进程进不了临界区,任然会持续占有cpu
JAVA与GO中会使用TAS与Mutex结合的锁,先自旋,到达一定时间,在陷入内核
deschedule? Reader-Writer Latches
一般基于前两者来实现,但是会区分读写模式,通过添加元数据,当然这需要DBMS花费更多的维护成本去避免Thread的饥饿
hash table的latch不会死锁, 因为它是按顺序加锁的 所有的线程的访问顺序都是一致,并且一次只访问一个page/slot 粒度可以变化,可以是page锁(page latch减少了并行度)或者是slot锁(slot锁增加了并行度,但是增加了维护latch的开销,因为每个slot都需要一个latch,当然可以通过只用一种锁,也就是不区分读写,来减少latch的元数据与计算开销),粒度越细,越能避免并发冲突的问题,但是会使得锁的数量变多 B+树的并发 与 latch
B+树的并发 与 latch
B+树需要保证两个方面的并发问题: 多个线程去修改同一个叶节点的内容 当一个线程在遍历树时,另外一个线程在分裂或者合并节点 B+树的并发控制策略 latch carbbing/coupling,其基本原则是: 先给parent节点加锁 再给child节点加锁 释放parent节点的锁,如果这样做被视作是安全的,一个安全的节点是指它不会分裂或者是合并当更新它时从正确性的角度看,释放latch的顺序并不重要,但是从性能的角度看,比较重要,最好是先释放高层节点的锁,因为如果高层节点被加上write latch,会使得其他thread连read都不行
对于search与未优化版的一样,但是对于设计Write的操作,可以先用乐观锁,也就是假定需要发生节点合并与分裂的概率很低,全程使用read latch;当真正发生节点合并与分裂时,再终止重头来过,这一次使用悲观锁,也就是write latch
对于top to down的寻找leaf node,并不会发生deadlock,因为一个线程只能够从上到下的获取latch
但是leaf node scan会发生deadlock,
做标记和写33不是一样耗费时间吗,延迟的意义何在?
例子没看懂? |





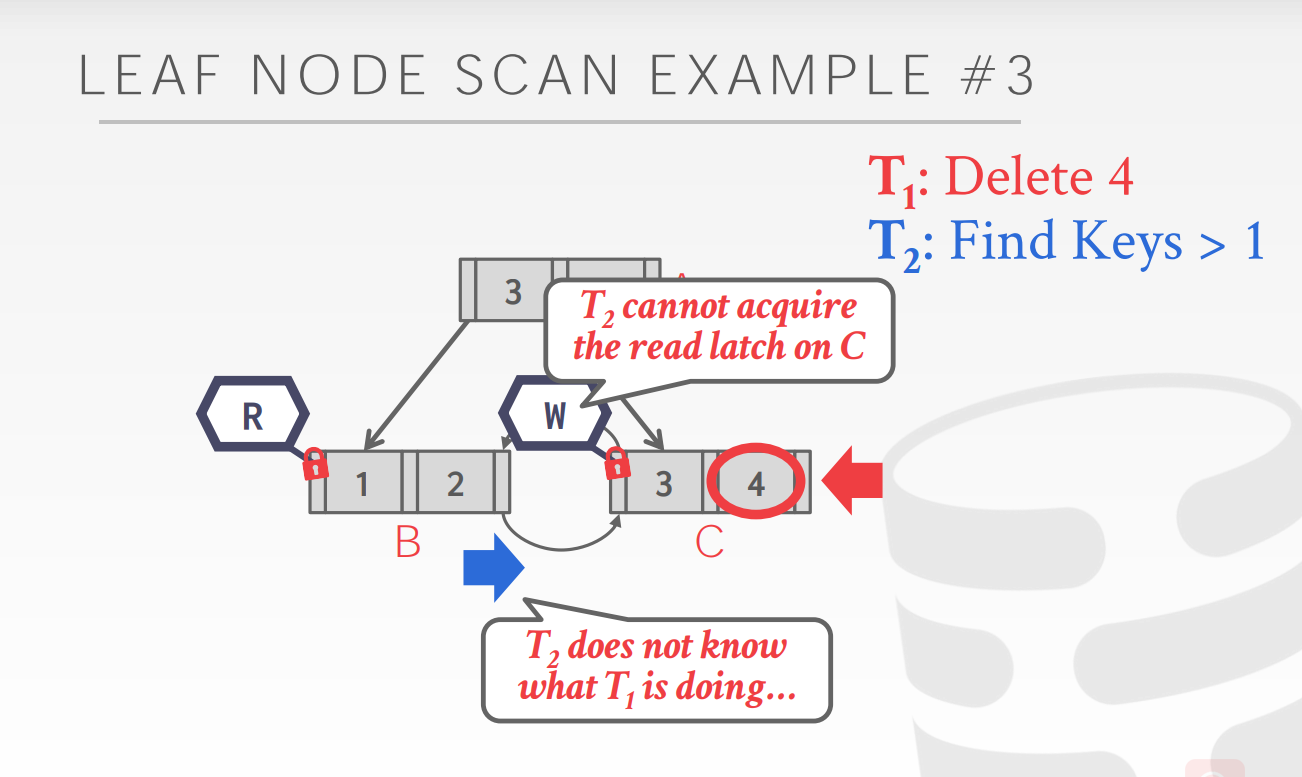 可以通过以下方法解决leaf node scan时的dealock
可以通过以下方法解决leaf node scan时的dealock


【本文地址】